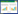 图 1(Fig.1)
图 1(Fig.1)



基于深度学习的视频人群计数系统
向东,
卿粼波,
何小海,
吴晓红
太赫兹科学与电子信息学报  2020, Vol. 18 Issue (3): 515-519 DOI: 10.11805/TKYDA2019234 2020, Vol. 18 Issue (3): 515-519 DOI: 10.11805/TKYDA2019234
|


视频监控中的人群计数一直是视频监控领域的研究热点,在实际的场景中具有广泛的应用价值,对于人群检测和场景理解具有重要意义,如通过分析道路人数来动态控制交通信号灯,优化管理行人流量、监控地铁站等交通枢纽的乘客数量、统计旅游景点客流量、监控重点公共场所安全等。因此,研究自动化、智能化的视频图像人群数量计算方法对于社会的有效分析和管理意义重大。人群计数的方法可分为传统的人群计数和深度学习驱动的人群计数两大类。传统的人群计数主要基于检测和回归方法[1],这类方法在处理密集场景时准确度较低;基于深度学习的人群计数[2−3]一般生成密度图来计数,但存在网络模型复杂,参数量巨大和计算量大的缺点,难以部署于实际应用场景。并且,现有人群计数算法绝大多数基于高性能的PC平台,无法实际部署在计算资源有限的嵌入式平台。同时,随着边缘计算的兴起,更快速的服务响应需求使得算法部署在数据源端成为必然趋势。但目前基于嵌入式平台的深度学习人群计数算法的研究较少,主要受限于嵌入式平台的资源有限和网络模型的庞大。因此,对网络模型进行裁剪压缩和加速[4−15]尤为重要。本文基于深度学习的方法对视频图像进行人群计数,对网络结构进行优化,并对网络模型进行压缩剪枝,最后结合TensorRT优化后部署在NVIDIA Jetson TX2嵌入式平台上,基本达到了实时人群计数的效果。
1 网络结构和网络模型优化 1.1 网络结构基于回归的人群计数关键在于生成高质量的人群密度图。本文的网络模型结构基于MCNN[8]的一个多分支的网络模型结构,如图 1所示。采用3列卷积核尺寸分别为7×7、5×5和3×3的卷积神经模块,使训练出来的模型对于拍摄角度和分辨率更具有鲁棒性,可以应对实际应用场景中拍摄角度变化和分辨率不同的问题;采用卷积核大小为1×1的卷积层代替全连接层,使模型可以接受任意大小的图像作为输入。本文设计的系统可以对任意分辨率的监控摄像头视频[14]进行实时人群计数,输入一个视频序列,模型输出相应的人群密度图,然后通过对密度图积分得到最终的人群计数结果。因此,高效的、高质量的人群密度图是深度学习应用在视频人群计数的关键。
 |
| Fig.1 Structure of network model 图 1 网络模型结构示意图 |
随着深度学习算法研究的不断深入,网络的层数不断增加,网络模型参数数量也在不断增加。虽然准确率在逐渐提升,但模型参数消耗的内存和计算资源也在提升,庞大而冗余的模型只能在高性能PC平台下运行,难以移植到计算资源有限的嵌入式平台上。因此,设计紧凑的模型结构,并对模型进行压缩和加速,成为亟待解决的问题。
目前针对单幅图像的人群计算网络在不考虑推理时间和消耗资源的情况下,在数据集上可以达到较高的准确度,但模型参数量巨大,只能止步于理论研究,很难具有实际应用价值。针对已有的网络模型存在较大的冗余,某些参数或卷积核对最终的预测结果作用不大或不明显,本文在提出简洁的网络结构基础上,对预先训练好的网络模型进行裁剪压缩。
剪枝的主要过程为:首先加载预训练好的模型,其结构如图 1所示,其准确度和可用性在2.1节中进行了测试和验证;然后获取准备剪枝的卷积层信息,计算准备剪枝的卷积核滤波器个数,每个滤波器对应生成一个特征图,这些特征图包含了相应的特征信息;由卷积核滤波器的总数和准备剪枝的卷积核滤波器得到需要迭代剪枝的次数。对网络进行一次前向传播,取得特定的卷积层的每一个通道经过激活层的输出作为对卷积层的评价标准,对每一层的输出的L2范数进行计算,如式(1)所示,x表示卷积层通道经过激活层后的输出,根据L2范数大小进行排序,选取N个最小值作为被剪枝的滤波器核,然后生成掩模矩阵将选中的滤波器核剪去,再对模型进行微调训练。通过这种迭代裁剪和Retrain的方式恢复网络模型的部分性能,避免裁剪导致过多精确度损失。通过在测试集上进行测试,保证裁剪后模型的泛化能力。这样在减小网络模型大小的同时,可以保证网络模型精确度不至于下降太多,保持其良好的泛化能力。
| ${\left\| X \right\|_2} = \sqrt {\sum\limits_{i = 1}^n {{x_i}^2} } $ | (1) |
TensorRT是一个高性能深度学习推理平台,为深度学习推理应用提供低延迟和高吞吐量的服务,支持INT8和Float16数据类型优化。
TensorRT加速推理包含两个阶段:构建(Build)和部署(Deployment)。在构建阶段,TensorRT对网络配置进行优化,并生成一个优化过的Plan用于计算深度神经网络的前向传播。这个Plan是一个优化后的目标代码,可以序列化地存储在内存或磁盘上。在部署阶段,通常采用长时间运行的服务或用户应用程序的形式,该服务或用户应用程序接受批量输入数据,通过对输入数据执行Plan来进行推理,并返回批量输出数据。针对实时人群计数在嵌入式平台TX2上的应用需求,同时考虑TensorRT对于本文所用框架的支持性,本文采用TensorRT对模型部署进行优化加速。
优化推理过程如图 2所示,TensorRT优化对模型进行INT8量化之前,需对精确度为FP32的模型进行校验。在创建TensorRT优化推理图之前,首先调用create_inference_graph函数并设置precision_mode参数为INT8,以此对模型进行校准,输出一个精确度校准后的冻结TensorFlow图;接着使用与实际数据集分布相同或接近的校准数据运行校准图;最后将优化后的模型部署在TX2嵌入式平台上。
 |
| Fig.2 Reasoning process of TensorRT optimization 图 2 TensorRT优化推理过程 |
首先对3个单列神经网络进行预训练,然后再合并训练。训练时对原始数据集进行9次随机裁剪,得到9张图像子块,每个图像子块是原图的1/4,通过这样的数据增广方式使训练图像尺寸变小,以加快网络训练速度。网络采用Adam为优化算法进行训练,先在GCC Dataset[9]上预训练,然后在ShanghaiTech数据集上进行微调,模型实现基于Tensorflow为后端的Keras框架。本文采用GPU模式进行网络训练,硬件为基于Pascal架构的NVIDIA Titan X显卡,其显存为12 GB。训练完成后,进行网络裁剪压缩,并利用TensorRT进行推理加速,最后将实际模型部署在TX2嵌入式平台,通过接入监控摄像头进行实际场景的测试。对于视频序列图像,本文模型基于每一帧单独进行前向推理输出密度图,从而实现人群计数,计数结果在控制终端中实时更新,并且在显示监控图像时标记其对应的计数结果。本实验采用的平台基于Tegra Parker处理器,拥有256个CUDA核,浮点计算能力为1.5TeraFLOPS,对于终端化人工智能和深度学习开发具有独特的优势和潜力。网络卷积层裁剪前后参数对比见表 1。
| 表 1 网络卷积层裁剪前后参数对比 Table 1 Parametric comparison of network convolution layer before and after pruning |
本文在已训练的模型上应用了一种具有相对较低权重的滤波器修剪方法,以减少模型的参数量,且不会引入不规则的稀疏性[10]。如表 2所示,在ShanghaiTech B测试集上的测试表明,使用的迭代修剪和再训练策略使原模型大小降低约30%,但裁剪后的模型的MAE(计数平均绝对误差)与原模型相比并没有降低太多,对于一个实时的应用系统,在可接受范围。在TX2嵌入式平台上测试结果显示,TensorRT加速后的裁剪模型的MAE与未加速模型的MAE基本相当。但从表 2可以看出,模型在通过TensorRT加速后,在TX2嵌入式平台上,对于360×640大小的视频帧推理时间,相比于原模型缩短了64.5%。综上所述,采用的裁剪压缩方法和TensorRT加速方法,对本系统的实时效果起到了良好的作用。
| 表 2 裁剪前后模型性能对比 Table 2 Performance comparison of models before and after tailoring |
为验证模型对视频的人群计数的能力,本文采用2种方式进行测试:一是将ShanghaiTech B测试集的图片合成视频作为输入,部分样例测试结果如图 3所示;二是在实际场景中进行测试。在进行实际场景的测试前,先在一个自制的小型数据集进行微调训练,部分测试结果如图 4所示。图 5为BeijingBRT测试集的图片合成视频作为模型输入的部分测试结果。其中GT表示Ground Truth,即视频帧中真实的人群数目,estimated表示通过本文系统测试输出的人群数目。
 |
| Fig.3 Crowd counting results of ShanghaiTech B testset synthetic video 图 3 ShanghaiTech B测试集合成视频人群计数 |
 |
| Fig.4 Crowd counting results of campus canteen surveillance video 图 4 校园食堂监控摄像视频人群计数 |
 |
| Fig.5 Crowd counting results of BeijingBRT surveillance video 图 5 BeijingBRT监控摄像视频人群计数 |
本文针对视频中人群计数的应用背景,采用了一个易于部署的深度学习网络模型,为了实现对视频序列进行接近实时的人群计数,应用了迭代裁剪滤波器的方法,通过裁剪对输出精确度贡献小的滤波器,再通过TensorRT加速,显著减少了前向推理所消耗的运算资源和运算时间,同时保留了模型的预测性能。在实际场景的测试中,实现了接近实时的人群计数。
| [1] |
PHAM V Q, KOZAKAYA T, YAMAGUCHI O, et al. COUNT forest: co-voting uncertain number of targets using random forest for crowd density estimation[C]// IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2016: 3253–3261.
|
| [2] |
SAM D B, SAJJAN N N, BABU R V, et al. Divide and grow: capturing huge diversity in crowd images with incrementally growing CNN[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 3618-3626.
|
| [3] |
CAO X, WANG Z, ZHAO Y, et al. Scale aggregation network for accurate and efficient crowd counting[C]// Proceedings of the European Conference on Computer Vision. Munich, German: Springer, 2018: 734-750.
|
| [4] |
ANWAR S, HWANG K, SUNG W. Fixed point optimization of deep convolutional neural networks for object recognition[C]// Proceedings of the IEEE Conference on Speech and Signal Processing. Brisbane, QLD, Australia: IEEE, 2015: 1131–1135.
|
| [5] |
MIKHAIL Figurnov, AIZHAN Ibraimova, DMITRY P Vetrov, et al. Perforated CNNs: acceleration through elimination of redundant convolutions[C]// 30th Conference on Neural Information Processing System. Barcelona, Spain: [s.n.], 2016: 947-955.
|
| [6] |
COURBARIAUX M, BENGIO Y, DAVID J P. Binaryconnect: training deep neural networks with binary weights during propagations[C]// Neural Information Processing Systems. Montreal, Quebec, Canada: [s, n, ], 2015: 3105–3113.
|
| [7] |
HAN Song, POOL Jeff, TRAN John, et al. Learning both weights and connections for efficient neural network[C]// Advances in Neural Information Processing Systems. Montreal, Quebec, Canada: [s.n.], 2015: 1135-1143.
|
| [8] |
ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016: 589-597.
|
| [9] |
WANG Q, GAO J, LIN W, et al. Learning from synthetic data for crowd counting in the wild[C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA: IEEE, 2019: 8198–8207.
|
| [10] |
HAN Song, LIU Xingyu, MAO Huizi, et al. EIE: efficient inference engine on compressed deep neural network[C]// Proceedings of the 43rd International Symposium on Computer Architecture. Seoul, Republic of Korea: IEEE, 2016: 243–254.
|
| [11] |
覃勋辉, 王修飞, 周曦, 等. 多种人群密度场景下的人群计数[J]. 中国图象图形学报, 2013, 18(4): 392-398. (QIN Xunhui, WANG Xiufei, ZHOU Xi, et al. Counting people in various crowed density scenes using support vector regression[J]. Journal of Image and Graphics, 2013, 18(4): 392-398.) |
| [12] |
徐超, 高梦珠, 查宇锋, 等. 基于HOG和SVM的公交乘客人流量统计算法[J]. 仪器仪表学报, 2015, 36(2): 446-452. (XU Chao, GAO Mengzhu, ZHA Yufeng. Bus passenger flow calculation algorithm based on HOG and SVM[J]. Chinese Journal of Scientific Instrument, 2015, 36(2): 446-452.) |
| [13] |
周治平, 许伶俐, 李文慧. 特征回归与检测结合的人数统计方法[J]. 计算机辅助设计与图形学学报, 2015, 27(3): 425-432. (ZHOU Zhiping, XU Lingli, LI Wenhui. People counting based on feature-regression and detection[J]. Journal of Computer-Aided Design & Computer Graphics, 2015, 27(3): 425-432.) |
| [14] |
聂勇, 张鹏, 冯辉, 等. 基于动作标准序列的3D视频人体动作识别[J]. 太赫兹科学与电子信息学报, 2017, 15(5): 841-848. (NIE Yong, ZHANG Peng, FENG Hui, et al. 3D video human motion recognition based on motion standard sequence[J]. Journal of Terahertz Science and Electronic Information Technology, 2017, 15(5): 841-848.) |
| [15] |
WANG Chuan, ZHANG Hua, YANG Liang, et al. Deep people counting in extremely dense crowds[C]// Proceedings of the 23rd ACM International Conference on Multimedia. New York, NY, USA: ACM, 2015: 1299-302.
|